NVIDIA GPU AI computers are purpose-built to support demanding AI workloads across defense, counter-UAS, autonomous, and C4ISR applications where real-time sensor processing and rapid decision-making are mission-critical. These platforms enable on-platform AI execution for intelligence analysis, threat detection, target recognition, and situational awareness while reducing dependence on backhaul connectivity in contested or bandwidth-limited environments.
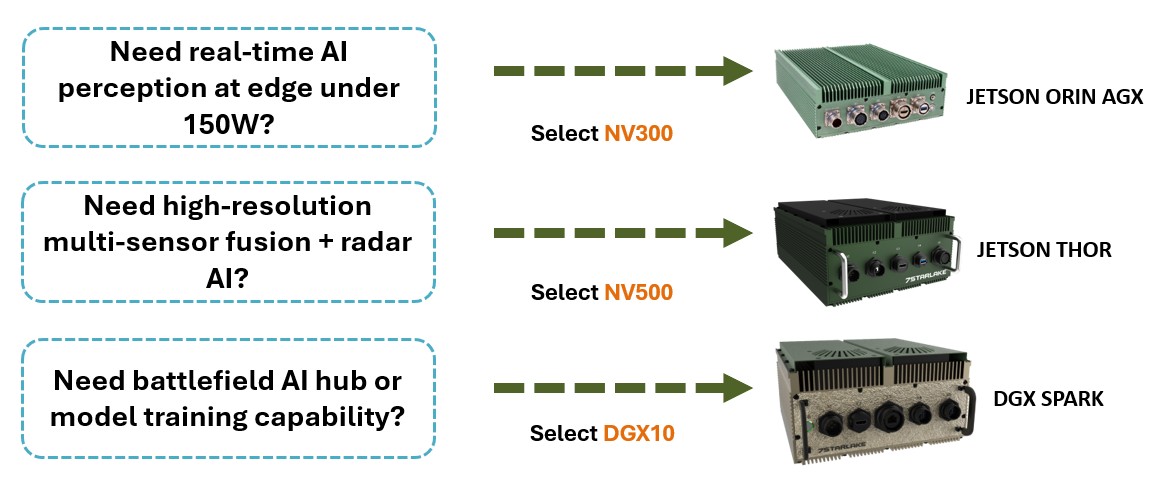
To address varying operational scales and deployment requirements, 7StarLake offers a structured AI computing portfolio built on three NVIDIA platforms, powering the tactical edge: NV300 powered by Jetson AGX Orin for distributed edge intelligence, NV500 based on Jetson Thor T5000 for high-performance fusion, and DGX10 utilizing DGX Spark GB10 for command-level AI aggregation and mission coordination.

Model |
Photo |
Sensor Layer |
Application |
Al Compute Level |
Positioning |
NV300(Orin AGX) |
|
EO/IR + RF(Single-Sensor) |
AI Targeting |
275 TOPS (INT8) |
Mid-levelreal-time edge AI |
NV500(Thor T5000) |
|
EO/IR + Radar +RF(Multi-Sensor) |
C-UAS Tracking &Classification |
2070 TFLOPS (FP4) |
High-throughputAI edge |
DGX10(GB10) |
|
EO/IR + Radar +RFGNSS, IMU, SDR, STCOM(AI Fusion) |
Perception Navigation |
1.0 PFLOP (FP4) |
Ultra-highAl Compute |
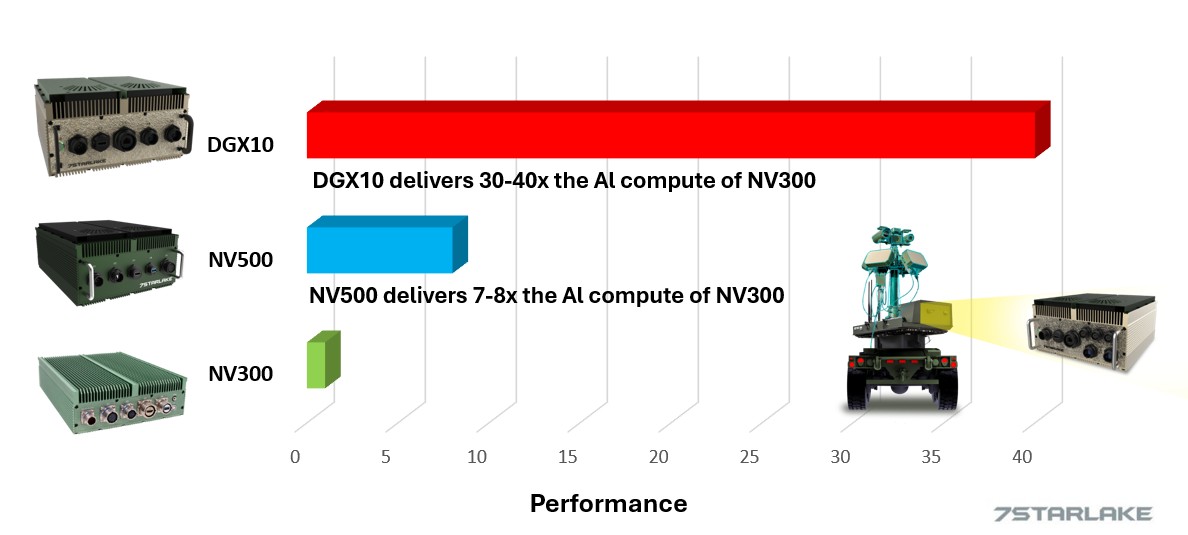
- Performance Scaling - AI Throughput Comparison
-
- Compute Architecture Comparison
-



Model
NV300
NV500
DGX10
CPU
12-core ARM
14-core ARM
20-core ARM
GPU

Jetson Orin AGX

Jetson Thor

DGX Spark
AI GPU
275 TOPS (INT8)
2070 TFLOPS (FP4)
1.0 PFLOP (FP4)
RAM
64GB
128GB
128GB
Storage
64GB eMMC
1TB
2TB
Networking
2x1G + 2x3G-SDI
1x100G + 1x1G
2x200G + 1x10G
Power
12 - 32 VDC
12 - 32 VDC
12 - 32 VDC
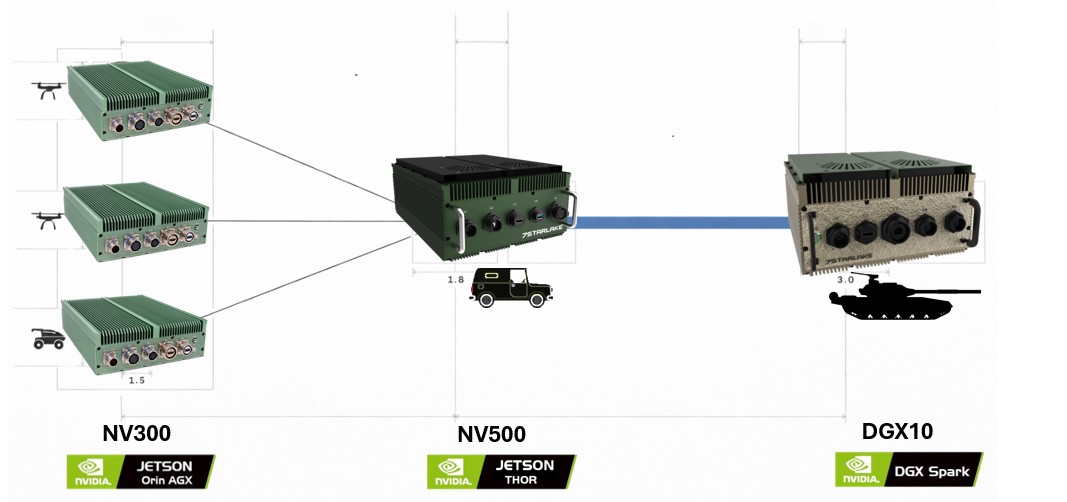
- Connecting Distributed Tactical Swarms Across Ground And Air
-
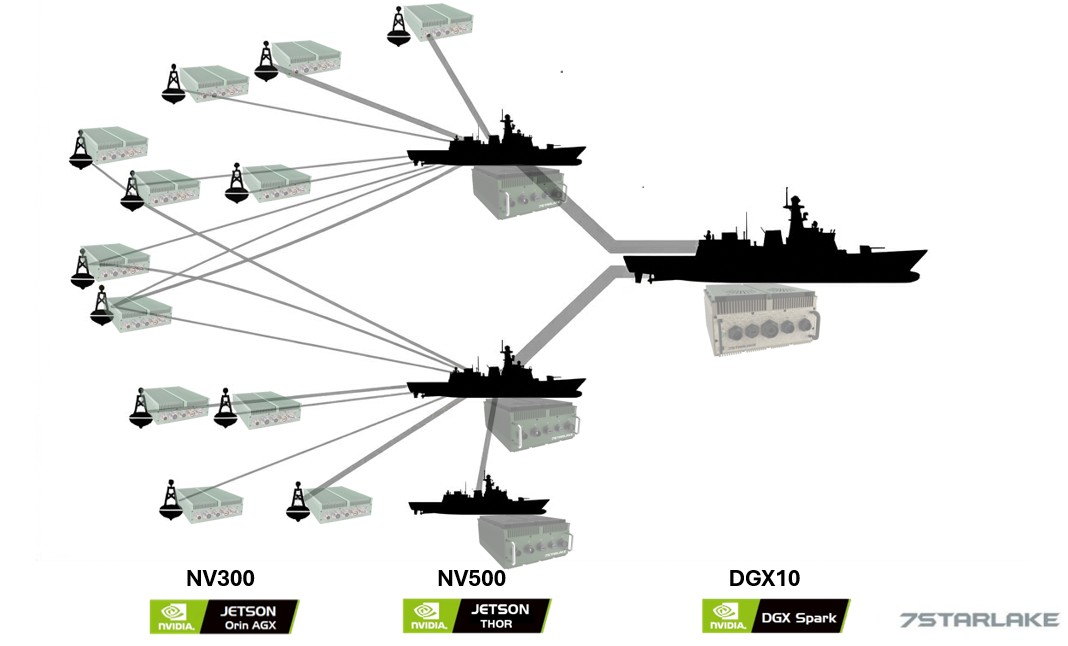
- Coordinating Maritime Operations Across USV Fleets
-
- NV300: The Foundational Tactical Edge AI Node
-

GPU: Jetson AGX Orin
Compute: 275 TOPS (INT8)
Net: 2 x 1G + 2 x 3G-SDI
Why Choose:
- Proven Orin ecosystem
- Cost-effective development at scale
- Low power 65W

Best for:
- Counter-UAV (single sensor)
- EO/IR + Basic RF
- Autonomous UGVs
- Al video analytics
- NV500: The High-performance Edge AI Brain
-

PU: Jetson Thor T5000
Compute: 2070 TFLOPS (FP4)
Net: 1x100G + 1x1G
Why Choose:
- Massive jump in Al throughput
- 100G networking for extreme data ingestion
- Native support for large transformer-based models

Best for:
- Advanced multi-sensor fusion (EO/IR + RF + Radar)
- C-UAS tracking & classification
- USV mother ship autonomy
- Al-based EW signal processing
- High-resolution radar processing
- DGX10: The Tactical AI Super Node
-

GPU: DGX Spark GB1O
Compute: 1.0 PFLOP (FP4)
Net: 2 x 200G + 1 x10G
Why Choose:
- 1 PFLOP-class AI throughput
- 200G networking for massive sensor aggregation
- Uncompromised large model support

Best For:
- Model training and fine-tuning
- Multi-model fusions
- Perception + Navigation
- Radar subsystem super nodes
- Select the Optimal NVIDIA AI GPU Servers
-